
The Three Pillars of Modern Machine Learning
In today’s technology-driven world, “Artificial Intelligence” has evolved from an academic concept into a foundational business tool. While the term is used broadly, the practical power of AI is unlocked through specific machine learning models designed to solve distinct problems.
For professionals and leaders, understanding the architecture of these models is no longer optional; it is a strategic necessity.
The ability to distinguish between the core paradigms of machine learning is the first step toward building, deploying, and capitalizing on intelligent systems.
This article serves as a definitive guide to the three fundamental pillars: supervised, unsupervised, and reinforcement learning.
We will define each approach, explore its core mechanics, and provide practical examples. By understanding their unique strengths, you can identify opportunities and make informed decisions about how AI can drive value in your domain.
Supervised Learning: The Power of Labeled Data
Supervised learning is the engine of optimization in the modern enterprise.
When you have a known target, predicting customer churn, forecasting sales, or identifying manufacturing defects, and the historical data to prove it, this paradigm provides the most direct path to measurable ROI.
It is the established workhorse of modern AI, forming the backbone of countless applications we use daily. Its strategic value lies in making accurate predictions from historical data.
The Core Concept: Learning from a “Teacher”
The fundamental principle of supervised learning is best understood through the analogy of an apprentice learning from a master.
The “master” is not a person but the organization’s accumulated wisdom, captured in its historical, labeled data.
The algorithm is given a dataset where the “right answers” are already known. This dataset consists of features (the input variables, like a house’s size and location) and a target variable (the output to predict, like its final sale price).
The algorithm’s goal is to learn the underlying pattern that connects the inputs to the correct output. By training on thousands or millions of these examples, it learns to replicate and scale the organization’s wisdom, making accurate predictions on new, unseen data.
Key Tasks and Real-World Applications
Supervised learning excels at two primary types of tasks: classification and regression.
Classification is the task of predicting a discrete category or class. The output is a label, not a number. When comparing supervised vs unsupervised learning examples, classification stands out as a core supervised task.
Applications include email filters learning from messages labeled ‘spam’ or ‘not spam’, image recognition models trained on vast libraries of labeled photos, and sentiment analysis systems that categorize customer reviews based on feedback labeled as ‘positive’ or ‘negative’.
Regression is the task of predicting a continuous, numerical value. Applications include financial algorithms analyzing market data to forecast future stock prices, real estate models using property features to predict a house’s market value, and retail systems predicting the quantity of a product that will sell next quarter based on past sales and seasonality.
Why is it called Supervised Learning?
The term “supervised” directly refers to the process of learning from a labeled dataset. The algorithm’s learning is guided, or supervised, by the presence of correct answers in the training data.
This supervision allows the model to measure its accuracy and correct its mistakes, much like a student being guided by a tutor.
But what happens when there is no answer key? When the goal isn’t to predict a known target but to discover the inherent structure of the data itself? This is the domain of the explorer, not the student, the world of unsupervised learning.
Unsupervised Learning: Discovering Hidden Patterns
Where supervised learning optimizes known processes, unsupervised learning discovers new opportunities.
It is the data-driven ethnographer, finding emergent tribes (customer segments) and rituals (association rules) within your data that your business has never formally recognized.
Its strategic importance lies in its ability to uncover hidden structures and insights within data that are invisible to human analysts, answering questions you didn’t even know to ask.
The Core Concept: Learning Without an Answer Key
Unsupervised learning algorithms operate on unlabeled data. There is no “teacher” and no answer key. The system is given a dataset and tasked with finding inherent patterns, groupings, or anomalies on its own.
Instead of predicting a known outcome, its objective is to understand the data’s underlying structure and organize the information in a meaningful way.
Key Tasks and Real-World Applications
The two most common tasks in unsupervised learning are clustering and association.
Clustering is the process of grouping similar data points. The algorithm determines the criteria for similarity and creates groups where members are more alike than they are to members of other groups.
Providing clear supervised vs unsupervised learning examples highlights this key difference. Marketing teams use clustering to segment customers based on purchasing behavior, revealing distinct personas for targeted campaigns.
Other applications include grouping thousands of news articles by topic or identifying unusual network activity that falls outside of any known cluster, flagging it as a potential security threat.
Association involves discovering rules that describe significant relationships between variables in large datasets.
The classic example is a retailer’s market basket analysis, discovering that customers who buy diapers are also highly likely to buy beer, an insight that can inform product placement.
E-commerce sites use association rules to power recommendation engines, discovering that users who view item X often also view item Y.
How Does Unsupervised Learning Work?
Unsupervised algorithms analyze the data’s intrinsic properties, such as distance, density, or distribution. For clustering, they might use these metrics to determine which data points belong together.
For association, they calculate the frequency of co-occurrence to identify strong rules. The process is entirely data-driven, allowing the model to reveal organic structures without human preconceptions.
The Definitive Comparison: Supervised vs. Unsupervised Learning
While both are powerful, their applications and methodologies are fundamentally different. Understanding the core distinctions in the supervised vs unsupervised learning debate is critical for any professional developing a data strategy.
The choice depends entirely on the problem to be solved and the nature of the available data.
A Head-to-Head Analysis
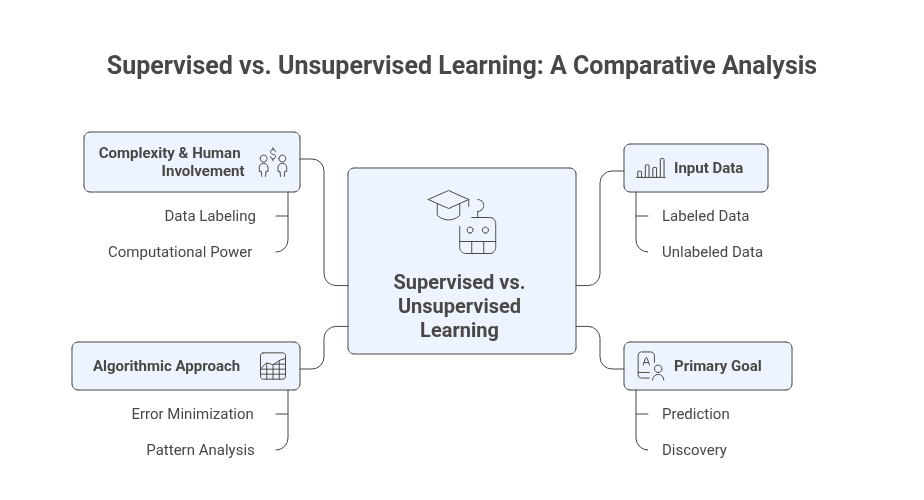
Input Data: This is the most significant differentiator. Supervised learning requires meticulously labeled data, where each data point is tagged with a correct output. Unsupervised learning works with unlabeled data, which is often more abundant and easier to acquire.
Primary Goal: The objectives are poles apart. The goal of supervised learning is prediction. It learns from the past to forecast the future, answering specific questions like “Is this email spam?”
The goal of unsupervised learning is discovery. It explores data to find hidden patterns, answering open-ended questions like “What natural groupings exist in my customer base?”
Algorithmic Approach: Supervised algorithms are trained to minimize the error between their predictions and the known correct answers. They are optimized for accuracy against a predefined target.
Unsupervised algorithms are designed to analyze the data’s inherent properties to organize it into meaningful structures. Success is judged by the quality and utility of the discovered insights.
Complexity & Human Involvement: The trade-off is one of investment versus ambiguity. Supervised learning demands a heavy upfront investment in the costly, human-intensive process of data labeling.
The return is a predictable, highly accurate model. Unsupervised learning requires less data preparation but demands more computational power and deep domain expertise to interpret its often ambiguous findings, trading upfront cost for the potential of paradigm-shifting discovery.
This brings us to the third major paradigm, which completes the supervised vs unsupervised vs reinforcement learning trifecta and operates on a different logic entirely.
Reinforcement Learning: Learning Through Trial and Error
Reinforcement learning is a dynamic, goal-oriented paradigm fundamentally different from the other two. It is concerned with how an intelligent agent ought to take actions in an environment to maximize a cumulative reward.
The concept is analogous to training a pet: you don’t give it an answer key (supervised) or ask it to find patterns (unsupervised); you reward it for good behavior. Over time, the pet learns the sequence of actions that leads to the most treats.
Core Concepts: Agents, Environments, and Rewards
Reinforcement learning is defined by a few key components: the agent is the learner (a robot or trading algorithm), the environment is the world in which it operates, actions are the possible moves it can make, and rewards are the feedback it receives.
The agent’s sole objective is to learn a policy, a strategy for choosing actions, that maximizes its total reward over the long term through trial and error.
Contrasting the Three Paradigms
The most critical distinction is that supervised and unsupervised models are trained offline on static datasets to produce a single answer or insight. In contrast, reinforcement learning agents are trained online by continuously interacting with a live or simulated environment.
They don’t just provide a prediction; they learn a policy, a complete strategy for sequential decision-making in the face of uncertainty. Unlike supervised learning, feedback is evaluative (“that was a good move”), not instructive (“the correct move was X”).
Unlike unsupervised learning, its exploration is purposeful, aimed at achieving a clear, long-term goal defined by a reward function.
Applications in the Real World
Reinforcement learning is exceptionally well-suited for problems involving complex decision-making in dynamic environments.
Its applications are among the most impressive in modern AI: training industrial robots to perform delicate assembly tasks, developing AI that achieves superhuman performance in strategic games like Chess and Go, optimizing traffic flow in smart cities, and creating financial algorithms that learn optimal trading strategies.
Conclusion: Choosing the Right Tool for the Job
The modern technology leader is an architect, not a spectator. Understanding these three paradigms is the blueprint. Supervised learning erects the pillars of optimization, unsupervised learning lays the foundation for discovery, and reinforcement learning builds the dynamic systems that interact with the world.
The choice between them is not about which is “better,” but which is the right tool for the job, hinging on the business problem, available data, and desired outcome.
The challenge ahead lies not in choosing one, but in architecting intelligent solutions that masterfully combine them all.
Frequently Asked Questions
What is the main difference between supervised and unsupervised learning?
The main difference is the data they use. Supervised learning uses labeled data (with correct answers) to make predictions, while unsupervised learning uses unlabeled data to discover hidden patterns.
Is ChatGPT supervised or unsupervised learning?
ChatGPT’s development involves both. Its foundation is built using a form of unsupervised or self-supervised learning on vast internet text, but its ability to follow instructions and be helpful comes from a crucial supervised learning phase called fine-tuning, guided by human trainers.
What is an example of unsupervised learning?
A classic example is customer segmentation, where an algorithm groups customers into distinct clusters based on their purchasing behavior without any pre-existing labels for what those groups should be.
Is LLM supervised or unsupervised learning?
Large Language Models (LLMs) are built using a multi-stage process. The foundational stage is ‘self-supervised’ learning, where the model learns from vast, unlabeled internet text. This is followed by a crucial ‘supervised’ fine-tuning stage, where humans guide the model to produce helpful and safe responses.
What is an example of supervised learning?
An email spam filter is a perfect example. It learns from a large dataset of emails that have been manually labeled as either “spam” or “not spam” to predict the category of new, incoming emails.
Is a robot an example of supervised learning?
A robot itself is a machine, but it can be trained using any of the three paradigms. A robot trained to identify objects from a labeled image library uses supervised learning. A robot learning to navigate a maze through trial and error uses reinforcement learning.
How does unsupervised learning work?
It works by analyzing the intrinsic properties of unlabeled data. For example, a clustering algorithm might measure the “distance” between data points and group those that are close together, thereby discovering natural segments within the data without external guidance.
Why is it called supervised learning?
It is called “supervised” because the learning process is guided, or supervised, by a dataset containing the correct answers (labels). The algorithm’s performance is constantly checked against these known answers, much like a student being supervised by a teacher.
How many algorithms are in supervised learning?
There are dozens of supervised learning algorithms, each with different strengths. Some of the most common include Linear Regression, Logistic Regression, Support Vector Machines (SVMs), Decision Trees, Random Forests, and Neural Networks.
What are the two most common supervised learning tasks?
The two most common tasks are Classification (predicting a category, like ‘spam’ or ‘not spam’) and Regression (predicting a continuous value, like the price of a house).
Is supervised learning better than unsupervised?
Neither is ‘better’; they are different tools for different architectural plans. Supervised learning is superior for predictive tasks with labeled data. Unsupervised learning is superior for exploratory analysis of unlabeled data. The architect’s skill lies in selecting the right tool for the specific business blueprint.



{kind=link}
{kind=link}
{kind=link}
Leave A Comment